Shuffle Introduction
Shuffle, as a bridge between map and reduce stages in map-reduce architecture, is the process to transfers mappers intermediate output to the reducer. The performance of shuffling is one of the biggest bottleneck in the distribute computation system that based on map-reduce architecture.
In the Apache Spark, three major steps are involved in the shuffle: Shuffle write, data transfer, and Shuffle read. The data transfer is passing shuffle write output on mapper side to reducer side as shuffle read input. Apache Spark implement its own RPC protocol based on Akka/Netty to achieve high performance, which will not be covered in detail in this article. On the other side, in order to mitigate the gap between memory and disk, optimizations are needed in shuffle write and read stages to minimize network traffic. A java object call workflow is shown in the figure below, which will be explained in detail in the rest of this article.
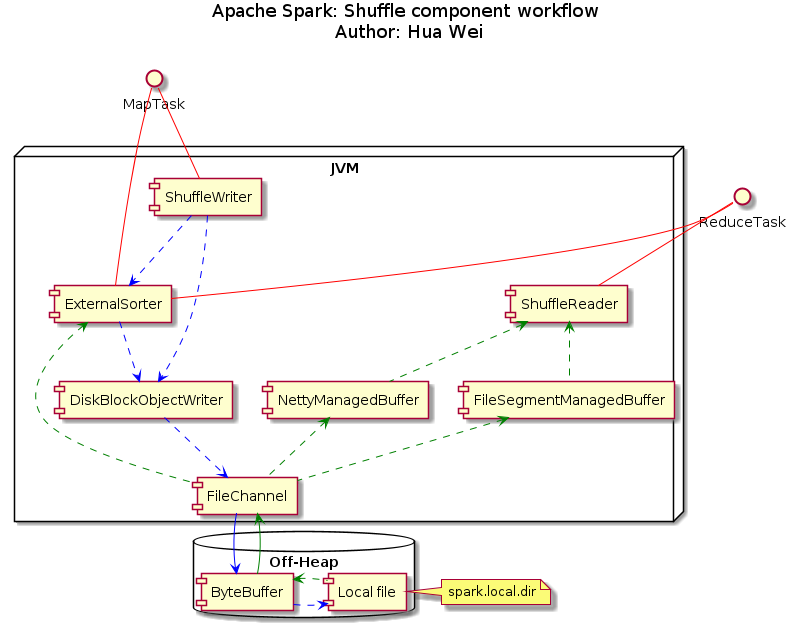
Shuffle Write
Shuffle Write, as its name indicates, is the stage load the output (e.g., MapPartitionsRDD) from map task, order the RDD according its key, and then write the data into disk, waiting for pulling request from reduce task. For example, given an Apache Spark application with one shuffle involved, three executors for map task and two executors for reduce task, then, each output from mapper side will be divided into two partitions, and each reducer will pull three partitions from each mapper. As a result, M (number of mapper) * R (number of reducers) partitions will be generated during shuffling. An shuffling RDD overview can be viewed in the plot below.
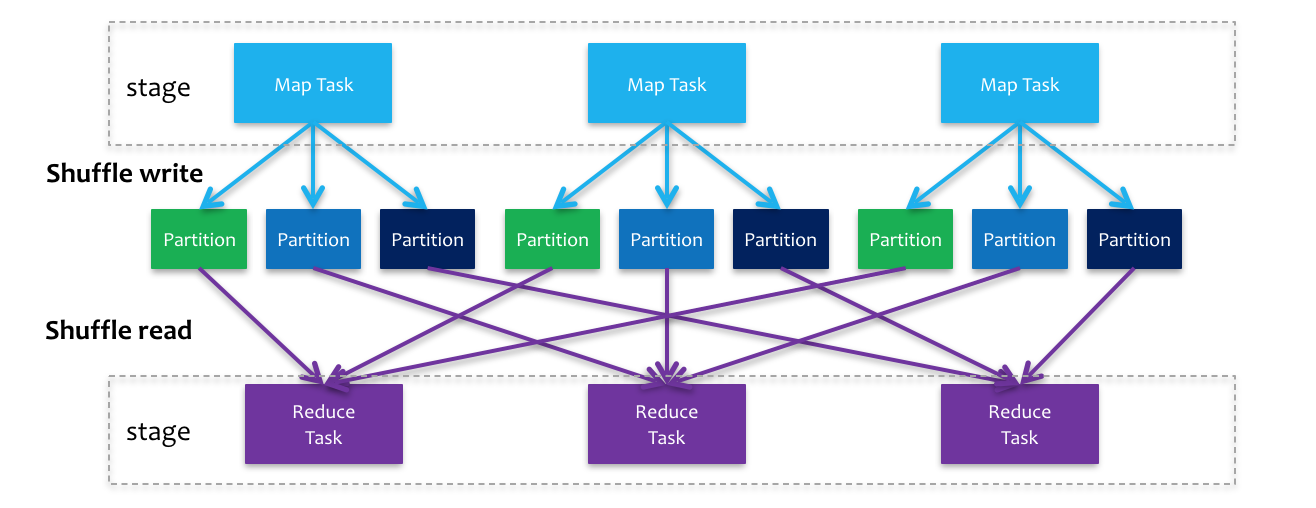
One of the most important thing for Shuffle Write is reduce the number of intermediate files. As mentioned above, number of M * R partitions are generated during shuffle. A straightforward approach is to save each partition into one single file, and each reducer can pull the target file directly (Hash Shuffle). However, the JVM Garbage Collection overhead will increase significantly when the size of Apache Spark cluster is large. To optimize this, one can merge all mapper side partitions into one file, and generate another index file to indicate its partition location. This is so called Sort Shuffle, which allow Apache Spark to be a large cluster as Apache Hadoop. Both Hash Shuffle and Sort Shuffle will be described in detail in the Shuffle Algorithms section.
Shuffle Read
After Shuffle Read, the Apache Spark RPC pull data over network from mapper side to reducer side. The Shuffle Read stage take data block from mapper partitions, and then merge them together.
Shuffle Algorithms
As we mentioned, one of the biggest performance bottleneck of the distributed computing system is to minimize the cost of data exchange among nodes. Apache Spark does a great job on this through DAG optimization and shuffle algorithm. Before Apache Spark version 1.2.0, Hash shuffle is used as default shuffle strategy. However, the number of files generated is proportional to M (number of mappers)* R (number of reducers), which is a bottleneck when cluster scaling horizontally. Sort shuffle is introduced as a solution to reduce the number of intermediate files.
Hash Shuffle
There are two versions of Hash shuffle that implemented as shuffle algorithm. The workflow of the first version can be viewed in the figure below. In this example, 4 ShuffleMapTask is running on the same executor, with two CPUs supported. The task output is first written into cache which is called as bucket. The default size of bucket is 32 KB, which can be tuned through configuration spark.shuffle.file.buffer.kb. Then, each bucket will be dumped into a small local file. This local file can be pulled by reducer accordingly as the input of reducers. In total, M (number of mappers) * R (number of reducers) small files are generated during Hash shuffle procedure.
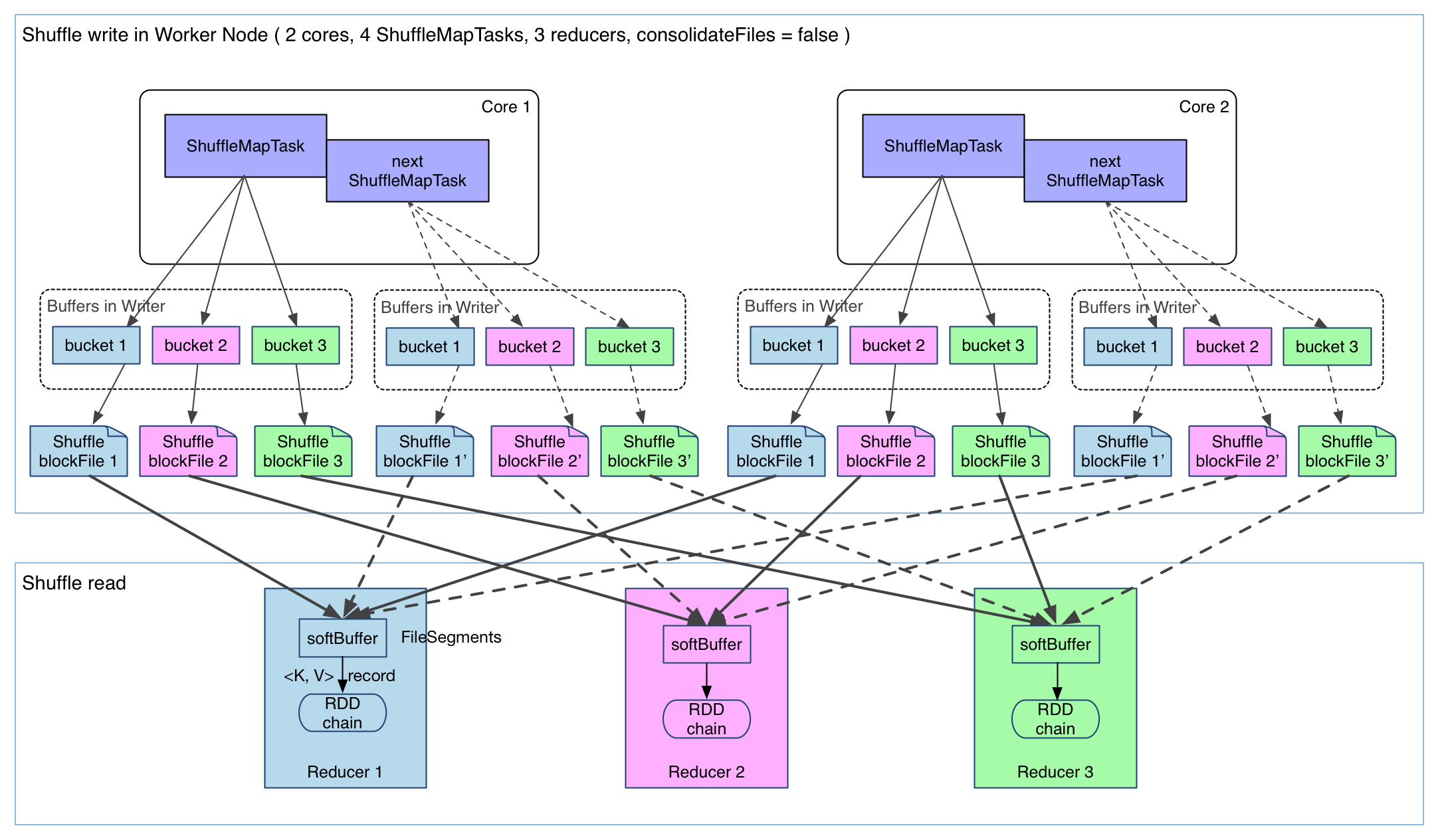
The version 1 is quite straight forward. However, there are two issues when number of partitions is big: 1, Too many file segment, which increase network IO pressure when transferring data from mapper side to reducer side. 2, Cache size occupation is large, which make garbage collection pressure and memory consumption. Therefore, Hash Shuffle version 2 is implemented to consolidate all file segment with one single file, which ease the issue 1 a lot. But issue 2 are still stay to be tuned.
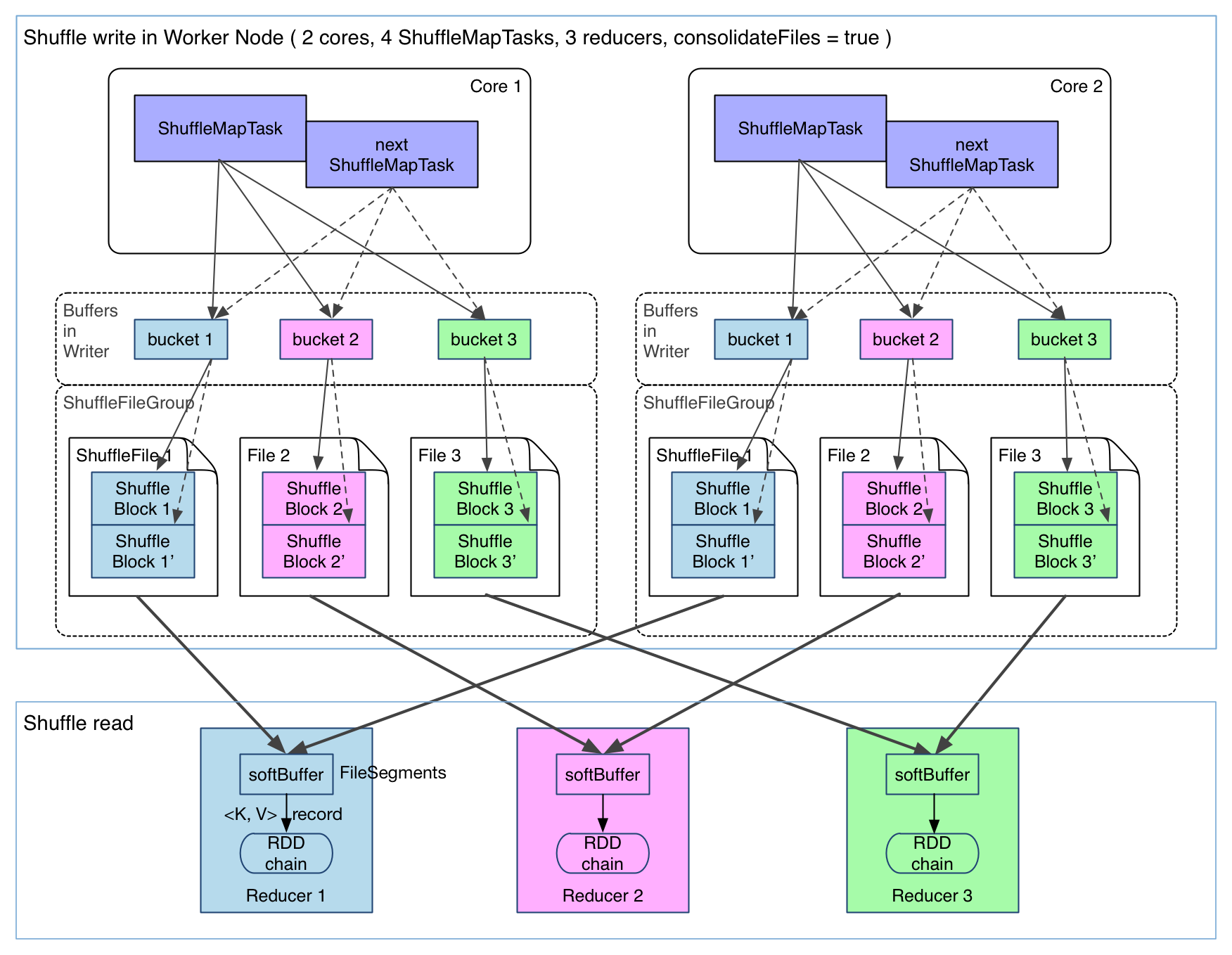
A summary of Hash Shuffle:
- Pros:
- CPU: No sorting, no hash function calculation.
- Memory/Disk: No space needed for external sorting.
- IO: Write once plus read once per partition.
- Cons:
- IO: Garbage Collection is costly when number of partitions is large.
- IO: Random instead of sequential IO in case of high pressure.
- Memory: Bucket take large size of cache when number of partition is large.
Sort Shuffle
In order to resolve the issues that come with Hash Shuffle, Apache Spark uses Sort Shuffle as default shuffle algorithm instead , like what Apache Hadoop project does. In the sort shuffle approach, the map output first goes to ExternalSorter, and then, the sorted result and its partition index are written into two files, respectively. The number of intermediate files decrease from R (number of reducers) to 2 on each mapper, and no buckets are allocated in the cache.
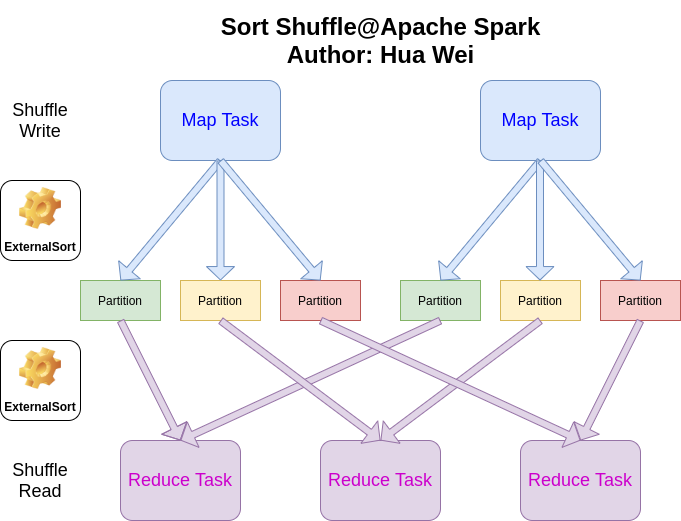
Sort Shuffle makes Apache Spark from a middle scale data processing platform to large scale data processing platform. However, it is not a silver bullet. Since external sort is needed, more CPU time and disk spaces are used during shuffle comparing with Hash Shuffle case. But, comparing with the system scalability, it is worthy to pay these prices.
Conclusion
In this article, a brief introduction of Shuffle in Apache Spark in described. The design and evolution of shuffle algorithm is described in high-level. More details, like source code implementation, Apache Spark RPC, etc, will be covered with more details in other article. One can also check additional readings below to get more detailed information.
More Readings
- TimSort, Peter McIlroy, Optimistic Sorting and Information Theoretic Complexity
- MapReduce
- v2.4.5, ShuffleWriter
- v2.4.5, ShuffleReader
- v2.4.5, DiskBlockObjectWriter
- v2.4.5, ShuffleMapTask
- v2.4.5, FileSegmentManagedBuffer
- v2.4.5, NettyManagedBuffer
- v2.4.5, SortShuffleWriter
- v2.4.5, ExternalSorter
- v2.4.5, ShuffledRDD
- v2.4.5, BlockStoreShuffleReader
- v2.4.5, ExternalAppendOnlyMap